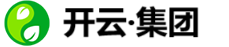
- 2025重庆公路客运联网售票中心有限公司招聘4人公告
- 工业40下数据采集新趋势:AI预测性维护如何突破数据孤岛?
- 没有MCP能力运维智能体就是“瞎忙”再强也白搭!
- 中国向全球宣布:又一张国家名片诞生!该技术全世界只有中国拥有
- 浪潮推出首个“人工智能工厂”工业化模式加速技术落地
联系人:王经理
手机:13928851055
电话:13928851055
邮箱:sgbwre@163.com
地址:广州市天河南一街14-16号华信大夏四楼
工业40下数据采集新趋势:AI预测性维护如何突破数据孤岛?
工业4.0的浪潮,我们已经谈论了将近十年。数字化、智能化的宏大叙事,早已响彻每一个制造车间的角落。然而,一个幽灵般的问题始终盘旋在许多企业上空:为什么我们投入巨资部署了无数传感器、升级了自动化产线,却依然感觉设备像一个个“最熟悉的陌生人”?我们努力进行
这,或许是当下制造业转型中最令人困惑的悖论。我们渴望数据,却又被数据所困。破局的关键,可能并不在于采集更多的数据,而在于一种全新的思维范式。今天,我们就来聊聊,作为工业4.0深水区的核心应用,AI预测性维护(AI-PdM)究竟是如何釜底抽薪,从根本上改变数据采集的逻辑,并最终击穿数据孤岛这堵厚墙的。
我们必须首先认清一个现实:传统的数据采集,其本质是一种“被动记录”。它忠实地记下设备运行的每一个参数——温度、压力、振动、转速……但这些数据本身,并不会说话。它们分散在不同的系统里——PLC、SCADA、MES——使用着五花八门的通信协议,就像一群说着不同方言的人,被关在同一个房间里,无法交流 。这就是数据孤岛的根源:物理上互联,逻辑上却彼此隔绝。
它的核心诉求,不是“记录已发生什么”,而是“预测将发生什么”。这个根本性的目标转变,对数据提出了前所未有的苛刻要求——它不再满足于零散、孤立、未经处理的原始数据。AI算法要想精准地从海量数据中识别出设备即将发生故障的微弱信号,就必须能够理解跨设备、跨系统、跨时间维度的所有关联信息 。
换句话说,AI预测性维护不是数据孤岛的又一个“租客”,而是它的“爆破者”。它以一种“需求倒逼供给”的强势姿态,迫使我们必须去构建一个能够让数据自由流动、对话、融合的全新架构。它把数据采集从一种单纯的技术动作,提升到了企业级的战略层面。
那么,AI预测性维护具体是如何驱动这场数据融合革命的呢?它并非依赖单一技术,而是一套精密的“组合拳”,这套组合拳正在成为工业数据架构的新范式。
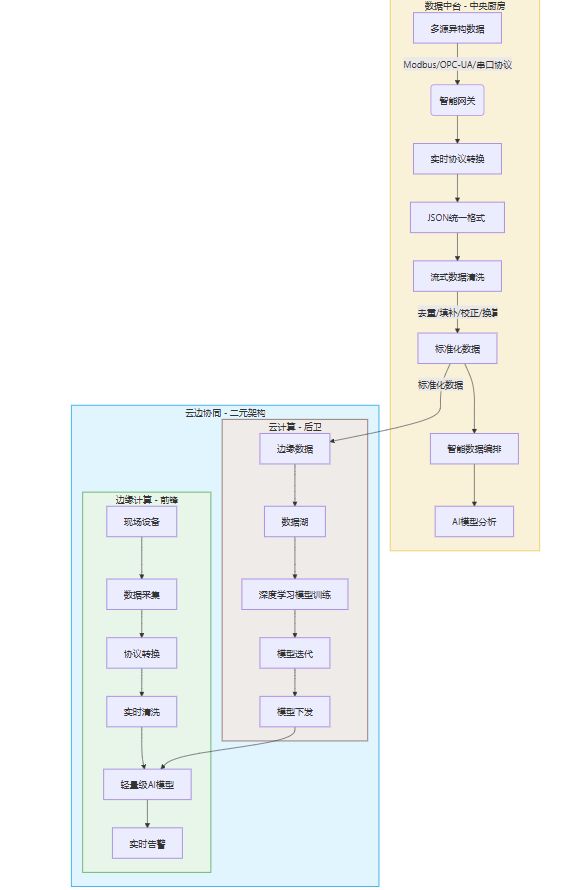
如果说各个设备是分散的“农田”,那么数据中台(Data Middle Platform)就是所有数据的“中央厨房”。它的核心使命,就是解决数据的“多源异构”难题 。
想象一下,来自A供应商的设备说的是“Modbus方言”,B供应商的设备讲的是“OPC-UA普通话”,而老旧的C设备可能还在用着某种自定义的串口协议。在过去,让它们对话几乎是不可能的。但现在,数据中台通过内置的强大能力,扮演了“超级翻译官”的角色。
其关键技术在于“实时协议转换”与“流式清洗”。通过在数据接入层部署智能网关或利用Netty等框架进行协议解析 数据中台能够将各种非标、异构的工业协议实时转换为统一的、可被理解的数据格式,比如JSON。这还不够,紧随其后的是“流式数据清洗”。利用Apache Flink、Kafka Streams这类流式计算引擎 流入的数据在毫秒之间就被完成去重、填补缺失值、校正错误、单位换算等一系列“精加工”动作。
经过这番处理,原本驳杂、混乱的原始数据,变成了干净、规整、随时可以“下锅烹饪”(即投入AI模型进行分析)的标准化“食材”。智能数据编排技术(Data Orchestration)则像一位总厨,自动化地调度和管理着整个数据的流动与处理过程,确保数据融合的无缝与高效 。
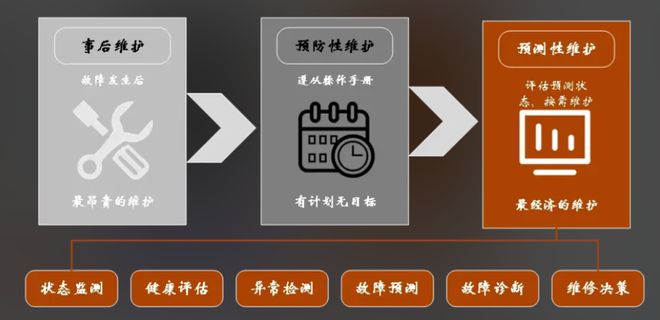
如果说数据中台解决了“数据能不能用”的问题,那么云边协同(Edge-Cloud Synergy)架构则解决了“数据在哪用、怎么用才最高效”的问题。这是一种典型的二元制衡与协作,也是当前工业数据处理最前沿的趋势 。
边缘端,就在生产现场,靠近数据源头。它的优势是——快!极低的延迟是它的天职 。对于那些需要秒级甚至毫秒级响应的场景,比如一个轴承的异常振动,等到数据上传到云端再分析,可能已经晚了。边缘计算节点负责就地完成数据的初步采集、协议转换和实时清洗,并运行一些轻量级的AI模型,进行实时的异常检测和告警 。这不仅极大提升了响应速度,还大幅降Kaiyun官方网站低了数据传输到云端的带宽成本和压力。
云计算与云原生(Cloud Computing / Cloud Native):运筹帷幄的“后卫”
云端,则扮演着“最强大脑”和“战略后方”的角色。海量的历史数据在这里汇入数据湖,用于训练和迭代那些极其复杂的深度学习预测模型 。云原生技术,如容器化(Docker)和编排系统(Kubernetes),提供了无与伦比的弹性和可扩展性,能够支撑起大规模、跨工厂的AI模型训练与管理任务 。更重要的是,在云端完成训练的、更智能的AI模型,可以被再次下发到各个边缘节点,实现整个系统智能水平的持续迭代和自我进化。
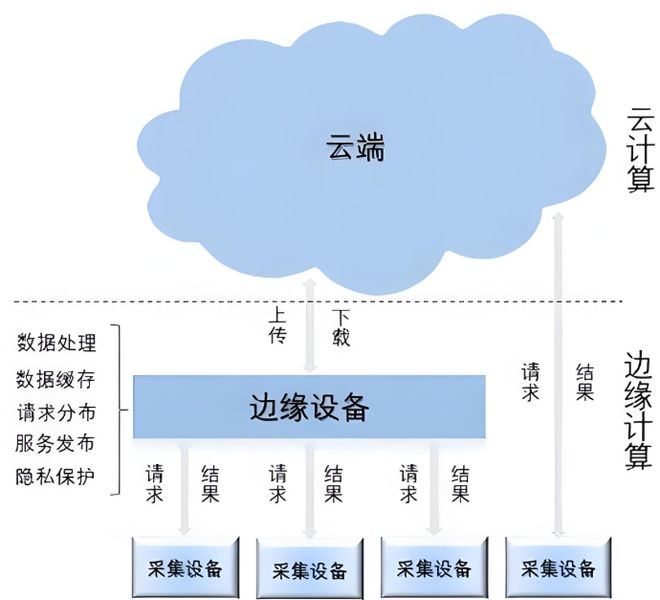
边缘与云,一个在现场雷厉风行,一个在后台运筹帷幄。两者通过协同,构建了一个从数据采集、实时分析、深度洞察到决策优化的完美闭环。
这种从“孤岛”到“融合”的转变,并非我们的一家之言,而是全球工业界正在形成的强烈共识。
在2025年汉诺威工业博览会上,“数据驱动的工业”(data-driven industry)成为了核心议题之一。在该展会备受瞩目的“领导者对话”(Leaders Dialogue)环节,来自德国电信集团(Telekom AG)董事会的成员Claudia Nemat,以及德国弗劳恩霍夫协会(Fraunhofer-Gesellschaft)主席Prof. Dr. Holger Hanselka等业界领袖共同指出,工业的未来竞争力,将直接取决于能否建立起一个贯穿从边缘到云端、无缝衔接的数据生态系统 。他们的讨论焦点,早已不再是“是否要数字化”,而是如何通过AI和数据融合,真正释放工业数据的潜在价值。
这清晰地表明,全球的行业先行者们,已经将打破数据孤岛、实现数据深度融合,视为通往下一代智能制造的必经之路。而AI预测性维护,正是这条路上最强大、最直接的驱动引擎。
答案已经清晰。它不是用一种新技术去修补旧架构的漏洞,而是通过提出一个颠覆性的应用目标,倒逼整个底层数据架构进行一次彻底的、自下而上的革命。它迫使我们必须建立数据中台这样的“中央枢纽”,必须采用云边协同这样的“立体化作战体系”。
最终,对于身处工业4.0浪潮中的每一位制造业同仁而言,真正的挑战已不再是技术选型,而是思维的破局。我们需要从过去那种“我的设备、我的数据”的部门墙、系统墙里走出来,转向一种“数据是全域资产、融合才能创造价值”的全新认知。
打破数据孤岛的征途,本质上不是一场技术的短跑冲刺,而是一场关乎战略与思维的马拉松。而AI预测性维护,恰恰就是这场马拉松中,那个最有力的领跑者,它正引领着我们,朝着一个真正智能、真正互联的工业未来,坚定地跑下去。
特别声明:以上内容(如有图片或视频亦包括在内)为自媒体平台“网易号”用户上传并发布,本平Kaiyun官方网站台仅提供信息存储服务。
顾客日料店消费4302元引热议,“以为是自助餐点了很多”,门店:点菜时已告知单价
一中国登山者在登顶乔戈里峰后被落石砸中当场死亡!“目前正进行遗体找回工作”
上海女游客在广西景区掉落价值5万钻戒上钻石,仅麦粒大小推测落入峭壁,求助民警找回
重拳封杀,出口同比暴跌59.2%:俄罗斯宣布禁售中国卡车,为何突然背后捅刀?
《编码物候》展览开幕 北京时代美术馆以科学艺术解读数字与生物交织的宇宙节律
据传下一代入门级iPad将搭载A18芯片 并支持Apple Intelligence
-
2025-08-152025重庆公路客运联网售票中心有限公司招聘4人公告
-
2025-08-15工业40下数据采集新趋势:AI预测性维护如何突破数据孤岛?
-
2025-08-15没有MCP能力运维智能体就是“瞎忙”再强也白搭!
-
2025-08-15中国向全球宣布:又一张国家名片诞生!该技术全世界只有中国拥有
-
2025-08-14边缘应用交付有难点?天翼云Serverless边缘容器来了!
-
2025-08-14CloudImagine
-
2025-08-14新型电力系统运行管理的创新之路
-
2025-08-14超融合架构狂飙突进!下一代数据中心市场新风口解析






 客服
客服