- 华为AI突破性技术揭晓!
- 刚刚华为AI突破性技术公布!英伟达花50亿才买到“同款”
- 2025鸿蒙生态应用市场发展报告
- 技术赋能价值共赢!琏升光伏天王星Pro、金星Pro异质结(HJT)多分片组件重磅发布
- 车网互动“日夜兼程” 重塑能源与交通新生态
联系人:王经理
手机:13928851055
电话:13928851055
邮箱:sgbwre@163.com
地址:广州市天河南一街14-16号华信大夏四楼
刚刚华为AI突破性技术公布!英伟达花50亿才买到“同款”
具体来看,Flex:ai是基于Kubernetes容器编排平台构建的XPU池化与调度软件,通过对GPU、NPU等智能算力资源的精细化管理与智能调度,实现AI工作负载与算力资源的“精准匹配”,进而提升算力资源利用率。
以软件补硬件提升AI训推效率、通过开放兼容降低软件开发难度,是其主要特点。
此前,英伟达于2024年4月以7亿美元(约合人民币49.7亿元)收购了以色列AI基础设施公司Run:ai,这家公司核心技术和产品就是提升GPU利用率,能够补充英伟达在AI计算资源管理领域的软件能力。
华为的Flex:ai有其“对标”的意味在,填补国内这一领域的空白,但同时开源的更加全面,相比RunKaiyun官网中国:ai的解决方案,在虚拟化、智能调度方面有其独特技术优势。
Flex:ai将在发布后开源在魔擎社区中,与华为此前开源的Nexent智能体框架、AppEngine应用编排、DataMate数据工程、UCM推理记忆数据管理器等AI工具共同组成了完整的ModelEngine开源生态。
华为特别提到,这项技术“从第一天起”就是高校一起合作开发的。在华为看来,开源是非常重要的,算力资源利用率的提升绝非“一概而论”,需要根据实际业务场景来分析,形成一系列算法。因此华为希望更多客户利用开源生态,将技术拿到自身实际业务场景中,共同探索、解决问题。
华为公司副总裁、数据存储产品线总裁周跃峰特别提到,华为更关注的是AI真正的行业化应用,关注tokens实现的价值而非总量。他们希望让更多企业真正用好AI,让AI进入生产流程中,实现增值,进而推动AI的平民化。
一、拆解Flex:ai三个关键能力:一张卡变N张卡、负载算力精准匹配、通算和智算融合
通过算力切分技术,将单张GPU/NPU算力卡切分为多份虚拟算力单元,切分粒度精准至10%。此技术实现了单卡同时承载多个AI工作负载,在无法充分利用整卡算力的AI工作负载场景下,算力资源平均利用率可提升30%。

通过全局智能调度器Hi Scheduler,自动感知集群负载与资源状态,结合AI工作负载的优先级、算力需求等多维参数,对本地及远端的虚拟化GPU、NPU资源进行全局最优调度,实现AI工作负载分时复用资源。即便在负载频繁波动的场景下,也能保障任务平稳运行。

聚合集群内各节点的空闲XPU算力聚合形成“共享算力池”,通用服务器通过高速网络将AI工作负载转发至池内GPU/NPU卡执行,实现通用算力与智能算力资源融合。

为什么要发布并开源Flex:ai AI容器技术?在华为看来,大模型时代,容器与AI是天然搭档。
容器技术作为一种轻量级虚拟化技术,可以将模型代码、运行环境等打包成一个独立的、轻量级的镜像,实现跨平台无缝迁移,解决模型部署“环境配置不一致”的痛点。容器还可以按需挂载GPU、NPU算力资源,按需分配和回收“资源”,提升集群整体资源利用率。
Gartner的分析师表示,目前AI负载大多都已容器化部署和运行,据预测,到2027年,75%以上的AI工作负载将采用容器技术进行部署和运行。
华为提到,当前传统容器技术已无法完全满足AI工作负载需求,AI时代需要AI容器。
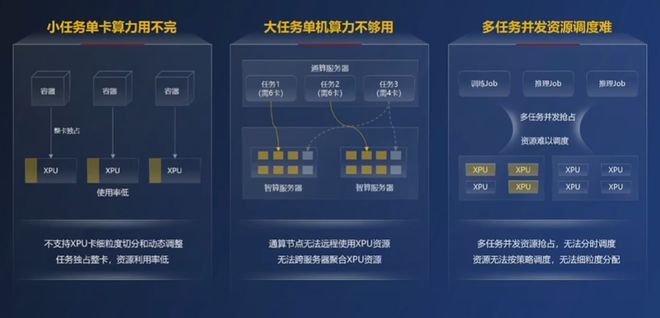
大型语言模型(LLM)的容器镜像轻松突破10GB,多模态模型镜像甚至可达TB级别,传统容器无法支持超大镜像的快速拉起,环境构建时间往往长达数小时。
传统容器主要针对CPU、内存等通用计算资源进行管理与调度,而AI大模型训练与推理还需大幅依赖GPU、NPU等智能算力资源,传统容器无法对异构智算资源做到算力细粒度切分与智能调度,导致即使很小的AI工作负载也独占整张算力卡,且无法进行远程调用。
传统容器的资源调度以固定分配、通用调度为主,而AI工作负载的资源调度需要以保障任务完成效率为目标,对不同任务的SLO特性进行感知,实现动态弹性的资源分配。
AI容器领域业界已经有多家企业推出了不同产品,与英伟达今年年初收购的Run:ai公司的核心产品相比,华为Flex:ai主要在虚拟化和智能调度方面有一定优势。
具体来看,在本地虚拟化技术中,Flex:ai支持把单个物理GPU/NPU算力卡切割为数个虚拟算力单元,并通过弹性灵活的资源隔离技术,可实现算力单元的按需切分。
同时,Flex:ai独有的“拉远虚拟化”技术,可以在不做复杂的分布式任务设置情况下,将集群内各节点的空闲XPU算力聚合形成“共享算力池”,此时不具备智能计算能力的通用服务器通过高速网络,可将AI工作负载转发到远端“资源池”中的GPU/NPU算力卡中执行,实现通用算力与智能算力资源融合。
智能调度方面,Flex:ai智能资源和任务调度技术,可自动感知集群负载与资源状态,结合AI工作负载的优先级、算力需求等多维参数,对本地及远端的虚拟化GPU、NPU资源进行全局最优调度,满足不同AI工作负载对资源的需求。
比如高优先级AI工作负载可以获得更高性能算力资源支持,在出现算力资源已被全部占满的情况下,能直接抢占其他任务资源,确保最重要的任务能够完成。而优先级较低的AI工作负载,则可以在算力闲时如夜间执行,实现分时调度;针对增量训练场景,Flex:ai还可智能感知集群中增量数据的变化,达到一定阈值后,触发数据飞轮。
现如今,不同行业、不同场景的AI工作负载差异较大,Flex:ai的开源,可提供提升算力资源利用率的基础能力和部分实践案例,随着更多产业玩家的加入,业界必将完成更多基于这一技术结合场景的落地探索。
与此同时,开源的Flex:ai可以在产学研各界开发者的参与下,共同推动异构算力虚拟化与AI应用平台对接的标准构建,形成算力高效利用的标准化解决方案,进一步加速AI的平民化。
特别声明:以上Kaiyun官网中国内容(如有图片或视频亦包括在内)为自媒体平台“网易号”用户上传并发布,本平台仅提供信息存储服务。
蔚来李斌:越来越精打细算,为省3万元“加班费”飞机改签,“我们要活下去慢慢来”
徐念沙会长在2025广州汽车发展高峰论坛 开幕式上的讲线黑骑士版首发亮相
全球首款2nm手机芯片!三星Exynos 2600采购价比高通骁龙8E5还便宜
iPhone 17e前摄升级为1800万像素:看齐苹果17 Pro Max
iPhone 18 Pro渲染图来了:酒红色机身+小号灵动岛 最美iPhone
-
2025-11-22华为AI突破性技术揭晓!
-
2025-11-22刚刚华为AI突破性技术公布!英伟达花50亿才买到“同款”
-
2025-11-22华为联合高校发布并开源AI容器技术 助力算力利用效率提升
-
2025-11-22算力利用率提升30%!华为联合三大高校开源AI容器技术 让闲置算力“活”起来
-
2025-11-22腾讯云对象存储服务(COS)
-
2025-11-22容器开发工程师腾讯招聘信息页介绍
-
2025-11-22腾讯云亮相2025香港金融科技周以“云+AI”助力全球企业数智化升级
-
2025-11-22腾讯云无锡峰会:腾讯云服务80%江苏头部民企 混元大模型等AI全栈产品加速进化






 客服
客服