- 万里长征黑料不打烊导航惊现震撼内幕揭露黑幕势力背后的惊天
- 天翼云申请一种分布式访问控制系统和方法专利能够提高访问控制的服务可用性
- 这些标杆场景 让新技术“绽放”
- 构建高性能容器化数据处理平台:使用kubernetes和apache flink
- 容器化数据平台-深度研究
联系人:王经理
手机:13928851055
电话:13928851055
邮箱:sgbwre@163.com
地址:广州市天河南一街14-16号华信大夏四楼
构建高性能容器化数据处理平台:使用kubernetes和apache flink
构建高性能容器化数据处理平台:使用kubernetes和apache flink
构建高性能容器化数据处理平台:使用kubernetes和apache flink
随着大数据时代的到来,数据处理需求越来越复杂,传统的数据处理方式已经无法满足现代化的需求。为了更好地处理海量的数据,提高数据处理的效率和性能,构建一个高性能的容器化数据处理平台成为了必然趋势。本文将介绍如何使用Kubernetes和Apache Flink构Kaiyun建一个高性能容器化数据处理平台,为企业提供快速、可靠、高效的数据处理解决方案。
随着互联网的快速发展和智能设备的普及,数据量呈爆炸式增长。企业需要处理海量的数据,并从中获取有价值的信息,以支持业务决策和创新。传统的数据处理方式面临着诸多挑战,如数据处理速度慢、可扩展性差、容错性低等。
容器化技术的出现为解决传统数据处理方式的问题提供了新的思路。容器化技术可以将应用程序及其依赖项打包为一个独立的容器,可以在不同的环境中运行,具有快速启动、轻量级、可移植等优势。容器化技术还可以提供资源隔离和自动化管理,提高了数据处理的效率和性能。
Kubernetes是一个开源的容器编排平台,用于自动化部署、扩展和管理容器化应用程序。Kubernetes提供了容器的调度、资源管理、服务Kaiyun发现、负载均衡等功能,可以帮助企业快速构建高可用性、可扩展性的容器化数据处理平台。
Apache Flink是一个分布式流处理和批处理框架,可以处理实时和离线的大规模数据。Flink提供了丰富的数据处理算子和API,支持事件驱动、Exactly-Once语义、容错性等特性。Flink还可以与其他数据处理工具和存储系统集成,如Kafka、Hadoop等,提供更强大的数据处理能力。
构建高性能容器化数据处理平台需要具备一定的硬件和网络环境,如高速网络、大容量存储、高性能计算资源等。企业需要根据自身的需求和预算来选择合适的硬件和网络设备,并进行相应的配置和优化。
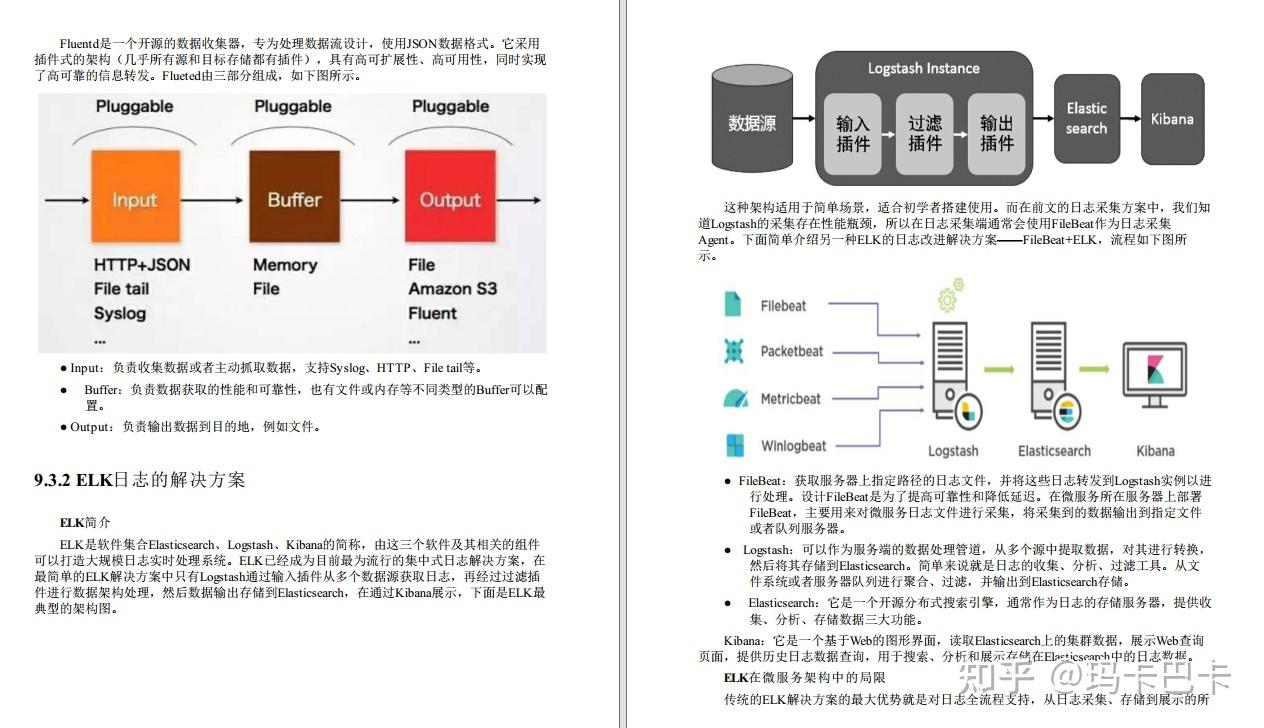
在构建容器化数据处理平台之前,需要先安装和配置Kubernetes集群。Kubernetes集群由多个节点组成,包括主节点和工作节点。主节点负责集群的管理和控制,工作节点负责容器的运行和数据处理。安装和配置Kubernetes集群需要遵循一定的步骤,如安装Docker、配置网络、设置认证和授权等。
一旦Kubernetes集群安装完成,就可以开始部署和管理Apache Flink应用程序了。需要将Apache Flink的镜像上传到容器仓库,并在Kubernetes集群中创建Flink应用程序的Pod。可以使用Flink的命令行工具或Web界面来提交和管理作业,监控作业的状态和性能。
构建高性能容器化数据处理平台的关键在于数据处理和存储。Apache Flink提供了丰富的数据处理算子和API,可以对数据进行实时处理、转换和分析。Flink还可以与其他数据存储系统集成,如Kafka、Hadoop、Elasticsearch等,提供更灵活和强大的数据处理能力。
构建高性能容器化数据处理平台可以应用于各个行业和领域,如金融、电商、物流、医疗等。以电商行业为例,可以利用容器化数据处理平台实时分析用户行为、推荐商品、预测销售等,提供个性化的购物体验和精准的营销策略。
对于构建高性能容器化数据处理平台的效果评估可以从多个方面进行,如数据处理速度、可扩展性、容错性、资源利用率等。通过对比传统数据处理方式和容器化数据处理平台的性能指标,可以评估容器化数据处理平台的效果和优势。
有益网络,始于2011年,拥有多年行业经验和专业的研发团队,用户放心之选。
-
2025-06-24万里长征黑料不打烊导航惊现震撼内幕揭露黑幕势力背后的惊天
-
2025-06-23构建高性能容器化数据处理平台:使用kubernetes和apache flink
-
2025-06-23容器化数据平台-深度研究
-
2025-06-23容器化大数据平台架构
-
2025-06-23这些央国企与中国500强企业选择了浪潮海岳PaaS平台
-
2025-06-23同方股份(600100)周评:本周涨028%主力资金合计净流出182276万元
-
2025-06-23生活服务平台搭建:数商云如何以技术驱动构建全场景服务生态
-
2025-06-23阿里云容器是什么






 客服
客服